
CMSACamp showcase website: https://www.stat.cmu.edu/cmsac/sure/2023/showcase/
Background:
Although I have only posted once so far, this one will diverge from the expected Open Source Sports model. The reason is because we (meaning the Department of Statistics & Data Science at Carnegie Mellon University) just wrapped up our summer undergraduate research programs yesterday. Similar to last year, we had two groups running simultaneously with one focusing on projects in healthcare and another in sports analytics (aka CMSACamp). Since the start of June, these students have been attending daily lectures on statistics & data science, statistical learning, and data engineering topics led by instructors Meg Ellingwood and Dr. Shamindra Shrotriya. We wrapped up the program yesterday with live presentations (short ten minute talks) and an engaging poster session. Students also wrote HTML reports summarizing their work, providing more detail beyond their slides and poster. All three mediums of their projects are available on the summer program showcase website.
Obviously I’m going to focus on the sports analytics projects in this newsletter, but you can check out the excellent healthcare projects by the students in that program by clicking on the showcase link.
Because I actually want you to read each of the students’ project reports, I’m only going to briefly provide you with an overview of the research question, a data visualization from the report, plus an interesting takeaway message. For some additional context, each CMSACamp project has an external advisor who pitches the project idea to the students (listed in the project descriptions below). This takes place in the first few weeks of the program while the students are knee-deep in lecture material and an EDA project with curated sports datasets. Once the students indicate their project preferences, they are then assigned to groups and effectively work on these intense research projects for the remainder of the program with their project advisors (along with day-to-day advising from TAs, which were Quang Nguyen, Yuchen Chen, and Nick Kissel this year). Ultimately, the students are working on these projects for just about a month before their presentations at the end of the program. I am always incredibly impressed by how much they accomplish in such a short period of time.
I hope you take the time to check out the work by these rising stars in sports analytics research, and make sure to attend our upcoming CMSAC in November where these students will be giving updated presentations!
(Projects listed in order of appearance on showcase website)
The Art of Sequencing: Utilizing Inter-Pitch Dynamics to Enhance Pitch Evaluation in Major League Baseball
Students: Priyanka Kaul (Harvard University), Ethan Park (University of Southern California), Evan Wu (Elon University)
External Advisor: Sean Ahmed, Pittsburgh Pirates
Report Link: https://www.stat.cmu.edu/cmsac/sure/2023/showcase/baseball/report.html
Research Question: Are the differences between a pitcher’s arsenal of pitches informative of pitch outcomes and how does that vary by pitch type?
Data Visualization: “Our graph shows that as Stuff+ increases, pitch usage tends to increase as well - indicating that pitchers do in fact throw their best pitches (as determined by Stuff+) more frequently. Our graph is colored by weighted on base percentage (wOBA) to further show that pitches with high Stuff+ ratings are correlated with lower opposing wOBA.”


Interesting Takeaway: So far, the students have observed that it’s hard to beat a simple GAM model with only Stuff+ as a feature in predicting out-of-sample xwOBA (i.e., pitchers should throw their best pitch). But their inter-pitch features did appear to improve prediction performance for breaking balls - indicating some potential signal of value in sequencing information.
To Bet or Not to Bet: Analyzing the Credibility of Fixed-odds Betting on Match Outcomes
Students: Fungai Jani (College of Wooster), Tsengelmaa Nyamdorj (Smith College), Maria Tsakalakos (Emory University)
External Advisor: Kostas Pelechrinis, University of Pittsburgh
Report Link: https://www.stat.cmu.edu/cmsac/sure/2023/showcase/soccer/report.html
Research Question: Can we improve predictions of soccer match outcomes beyond betting odds with additional information such as player and team evaluations?
Data Visualization: “Moreover, in order to best represent the model accuracy, we decided to use calibration plots, a visualization of disparity between the probability predicted by the model and the actual class probabilities in the data. The best model (init_logit_gam_pos) has its class lines predominantly closer to the 45 degree dashed line of perfect calibration. As for multinomial base models, it over-predicts match outcomes causing type II errors. Lastly, the base random forest has both type I and type II errors, which means the model is unfavorable for predicting match outcomes.”

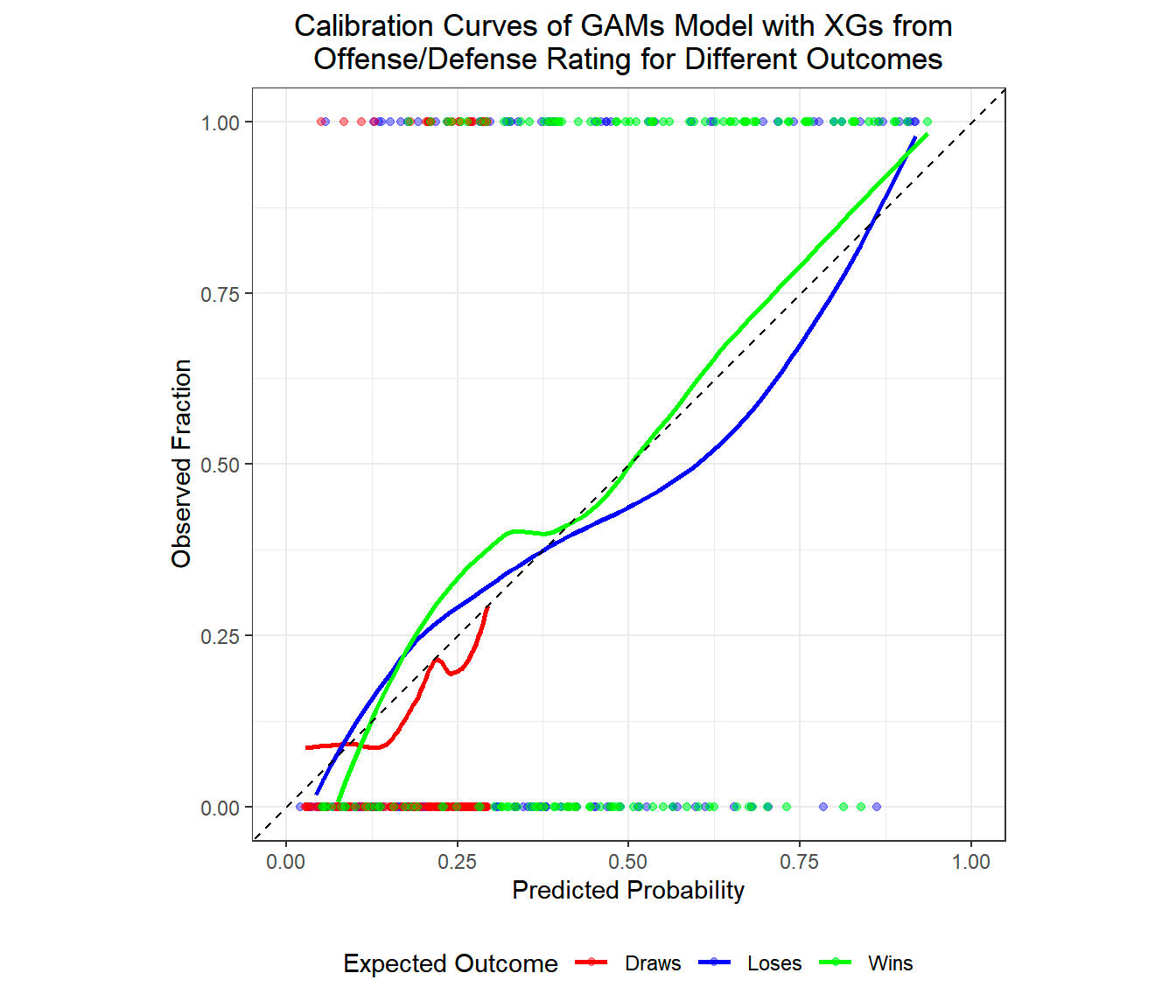
Interesting Takeaway: The students demonstrate improved predictions with their approach, and they see GAMs leading to better performance than more flexible random forests. Another win for regularization!
Examining the Decline of Save Percentage in the NHL
Students: Quinn Robnett (Syracuse University), Luke Welsh (University of Wisconsin-Madison)
External Advisor: Sam Ventura, Buffalo Sabres
Report Link: https://www.stat.cmu.edu/cmsac/sure/2023/showcase/hockey_saves/report.html
Research Question: To quote the students: “league-wide save percentage has been on a significant decline since 2016. In just eight seasons, save percentage has fallen from nearly .915 to a mere .904 in 2022-23. What’s going on here? That is what we will attempt to uncover.”
Data Visualization: The inspiration for the research question!

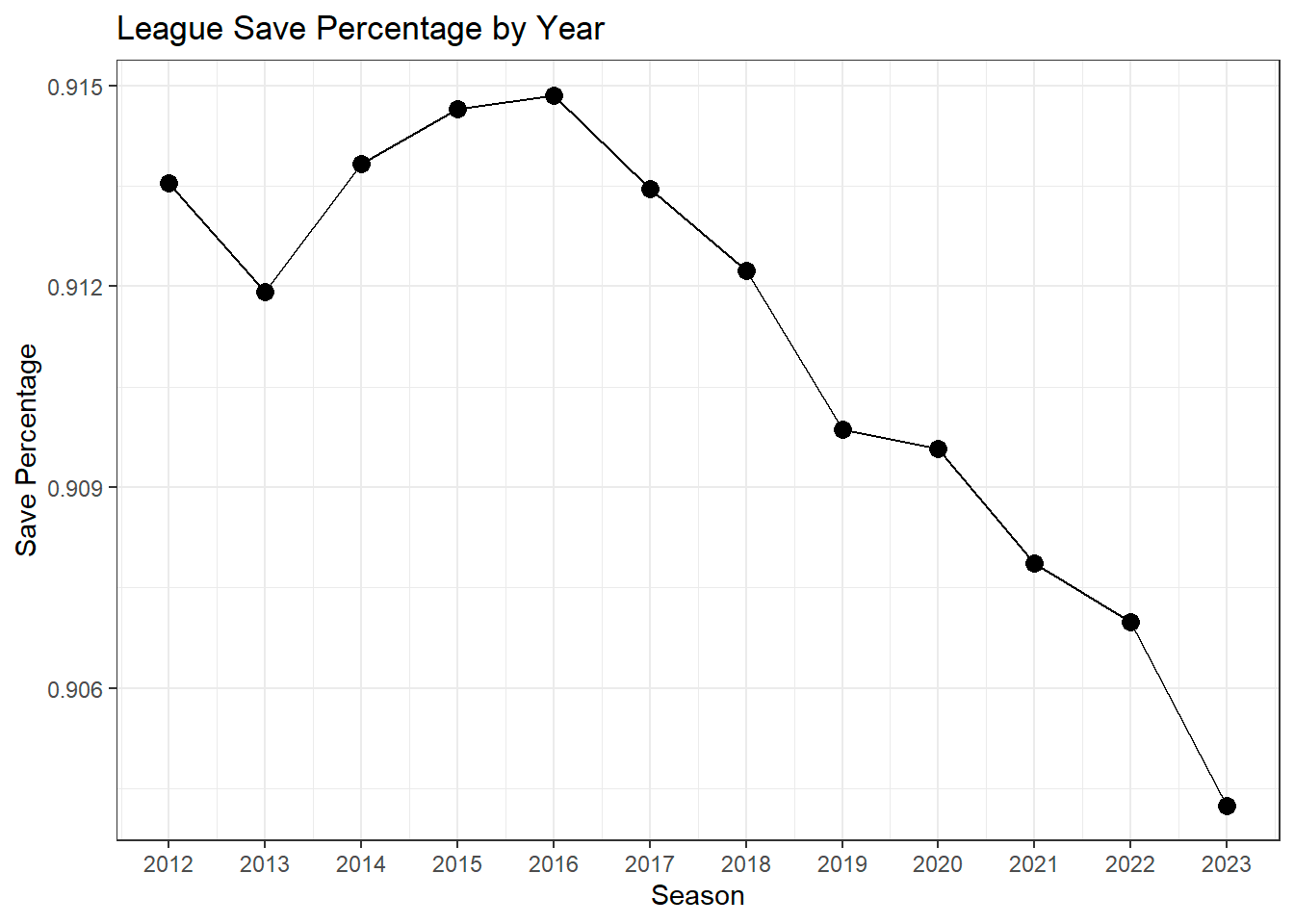
Interesting Takeaway: The students explored a variety of factors as to what could be driving the decline (e.g., backups playing more, are there more power plays?), but evidence suggests shot quality itself has improved.
Draw 2: Identifying the Key Players in Drawing NHL Power Plays
Students: Katherine Gong (Mount Holyoke College), Bethany Gonzalez (University of Indianapolis)
External Advisor: Katerina Wu, Pittsburgh Penguins
Report Link (all of their visuals are interactive!): https://www.stat.cmu.edu/cmsac/sure/2023/showcase/hockey_power_plays/report.html
Research Question: To quote the students: “what players in the league are the most successful in drawing power plays”?
Shiny App!: https://hhpr9d-katherine-gong.shinyapps.io/Draw_2/
Data Visualization:

Interesting Takeaway: The students revealed a key positional insight regarding penalties: “When considering players who take the same number of penalties, forwards draw a higher number of penalties compared to defense players. This pattern is evident in both the per 60 rate plot and the raw count plot. Forwards are more active in generating penalty opportunities due to their roles on ice.”

Clustering Race Horse Movement Profiles to Discover Trends in Injured Horses
Students: Sara Colando (Pomona College), Jonathan Pipping (University of Florida), Kristopher Wilson (North Carolina State University)
Advisor: Me…
External Advisor: Joseph Appelbaum, NYTHA
Report Link: https://www.stat.cmu.edu/cmsac/sure/2023/showcase/horse_racing/report.html
Research Question: Can we identify relationships between the types of movement profiles of horses in races via tracking data and link it to injuries?
Data Visualization: You’re going to need to read the report to understand this in detail, but the idea is that we can see that certain types of horse movement trajectories appear to be associated with severe injuries!
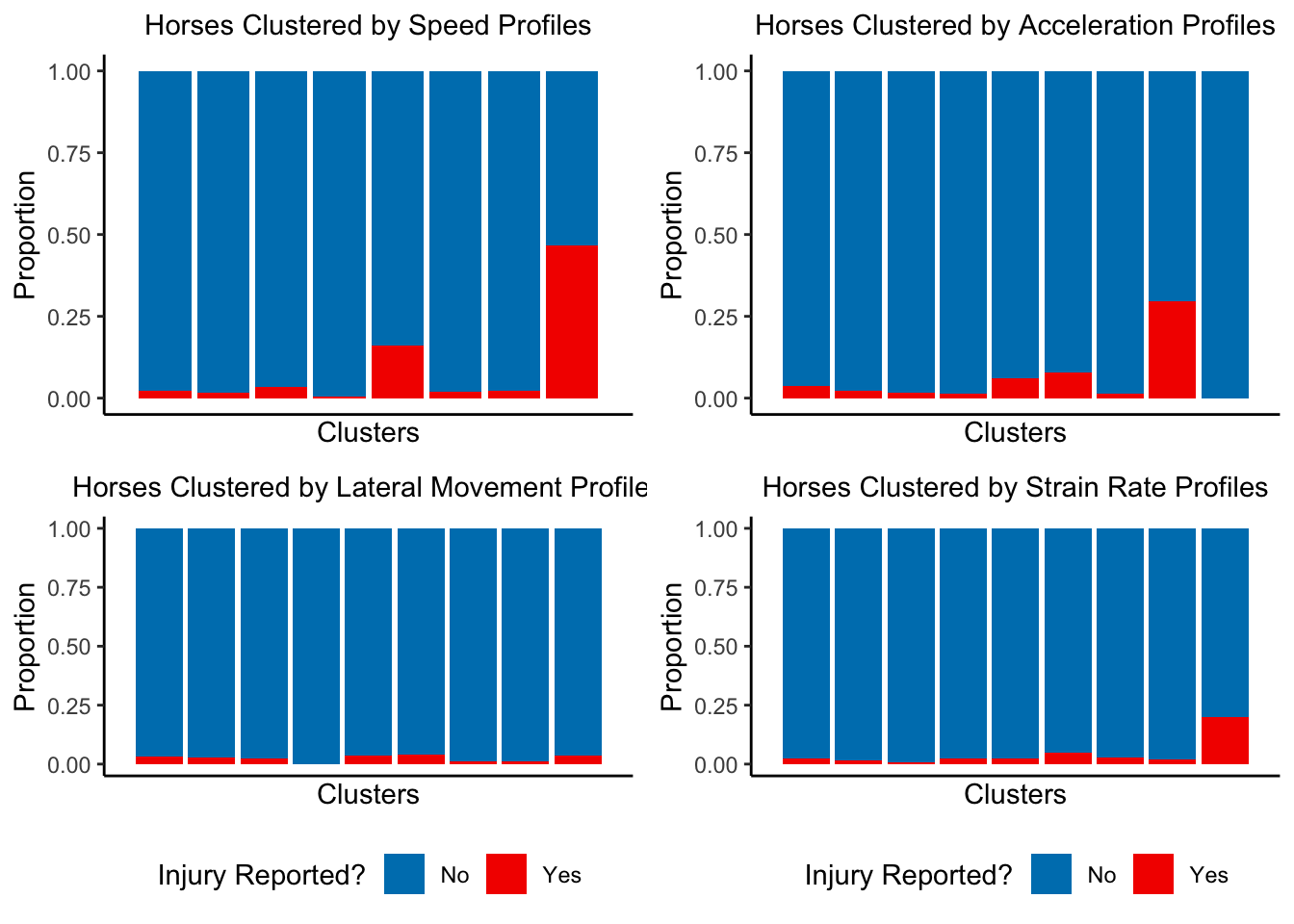
Interesting Takeaway: In addition to clustering information about tracking data movement, the students also built a negative binomial model for expected number of races based on horse-level information. The motivation for this was the concern that reported injuries are severe and likely low in signal strength. Using this model however, they observed that “horses who become severely injured are actually more likely to over-race than under-race relative to other horses their age in a given calendar year.”

Deal or No Deal: An NBA Recommender System for Team Composition and Salary Optimization
Students: Mathew Chandy (University of Connecticut), Leo Cheng (Carnegie Mellon University), Lauren Okamoto (University of California, Berkeley)
External Advisor: Max Horowitz, Atlanta Hawks
Report Link: https://www.stat.cmu.edu/cmsac/sure/2023/showcase/basketball/report.html
Research Question: This is a pretty ambitious project! The students state the following goals:
“Estimate which players are over or under-valued by predicting salary surplus in dollars.”
“Evaluate how players fit with each other by predicting the probabilities of events that lead to an increase or decrease in expected points.”
“Provide a list of recommended players to add to a four-man lineup based on salary surplus and how much a hypothetical team is willing to pay a player, whilst accounting for complimentary playstyles.”
Shiny App!: https://20wgki-mathewchandy03.shinyapps.io/shinyapp/
Shiny Demonstration (this is really cool, and I have no idea how they built this so fast!)


Interesting Takeaway: The students’ salary model coupled with clustering of players indicated “a significant divergence in salary rates but barely any difference in surplus values.”

