
CMSACamp showcase website: https://www.stat.cmu.edu/cmsac/sure/2024/showcase/
Background:
We recently wrapped up our summer undergraduate research programs in the Department of Statistics & Data Science at Carnegie Mellon University. Similar to last year, we had two student cohorts running simultaneously with one focusing on projects in healthcare and another in sports analytics (aka CMSACamp). Since the start of June, these students have been attending daily lectures covering a wide range of topics on data visualization, linear models, machine learning, and other relevant statistics and data science topics led by their instructor Quang Nguyen. Thanks to Quang, the students also connected with an all-star lineup of guest speakers that is far too long for me to include in this post. The program concluded with live presentations (short ten minute talks) and an engaging poster session. Students also wrote HTML reports summarizing their work, providing more detail beyond their slides and poster. All three mediums of their projects are available on the summer program showcase website.
I’m going to focus on the sports analytics projects in this newsletter, but you can check out the excellent student healthcare projects by clicking on the showcase link.
Since you should read each of the students’ project reports, I will briefly provide you with: (1) an overview of the research question, (2) an example data visualization from the report, and (3) an interesting takeaway they reached. For additional context, each CMSACamp project has an external advisor who pitches the project idea to the students (listed in the project descriptions below). This takes place in the first two weeks of the program while the students are knee-deep in lecture material and an EDA project with curated sports datasets. Once the students indicate their project preferences, they are then assigned to groups and effectively work on these intense research projects for the remainder of the program with their project advisors (along with day-to-day advising from Quang, myself, and teaching assistants). The students completed these projects in effectively one month, which is incredibly impressive given the high-quality analysis they generated (as you’ll see below).
I encourage you to take the time to check out the work by these rising stars, and make sure to attend our upcoming CMSAC in November where these students will be giving updated presentations! And we are still accepting abstracts for the Reproducible Research Competition until Friday August 2nd!
(Projects listed in order of appearance on showcase website)
Weapons of Best Production: Predicting the Optimal Pitch Arsenal Adjustment for Superior Stuff+
Students: Gabriel Eze (Centre College), Neha Kotha (University of Pittsburgh), Danny Nolan (Bucknell University)
External Advisor: Sam Fleischer, Los Angeles Dodgers
Report Link: https://www.stat.cmu.edu/cmsac/sure/2024/showcase/baseball_dodgers/report.html
Research Question: Can we create a pitch recommendation system that suggests the best pitch for a pitcher to add to their arsenal?
Data Visualization: “The plot below summarizes each model’s performance relative to the pitch acting as the response variable. For each pitch type, a random forest process produces the lowest average RMSE. This validated our belief that a random forest model was the best model to use and that the interactions within the predictor variables are indeed significant. We chose the pitch pairings that produced the lowest average RMSE to generate our Stuff+ predictions for each pitch type.”

Interesting Takeaway: The students demonstrated modeling one pitch type’s Stuff+ given the characteristics of another type of pitch. The above plot (where each point displays the average RMSE for a single response pitch ~ predictor pitch combination) shows the gains in out-of-sample predictive performance using a flexible tree-based approach that accounts for interactions, compared to an additive linear model. The students found a fantastic example with Ryan Pressly, where their approach indicated he would have an elite changeup given his curveball characteristics in 2021 and 2022 - before he started one in 2023!

Analyzing Consistency Among NHL Forwards Performance
Students: Celine (Zhongyang) Su (Wake Forest University), Chisunta Chikwamu (Whitman College), Cole Shegan Siniawski (Denison University)
External Advisor: Katerina Wu, Pittsburgh Penguins
Report Link: https://www.stat.cmu.edu/cmsac/sure/2024/showcase/hockey_penguins/report.html
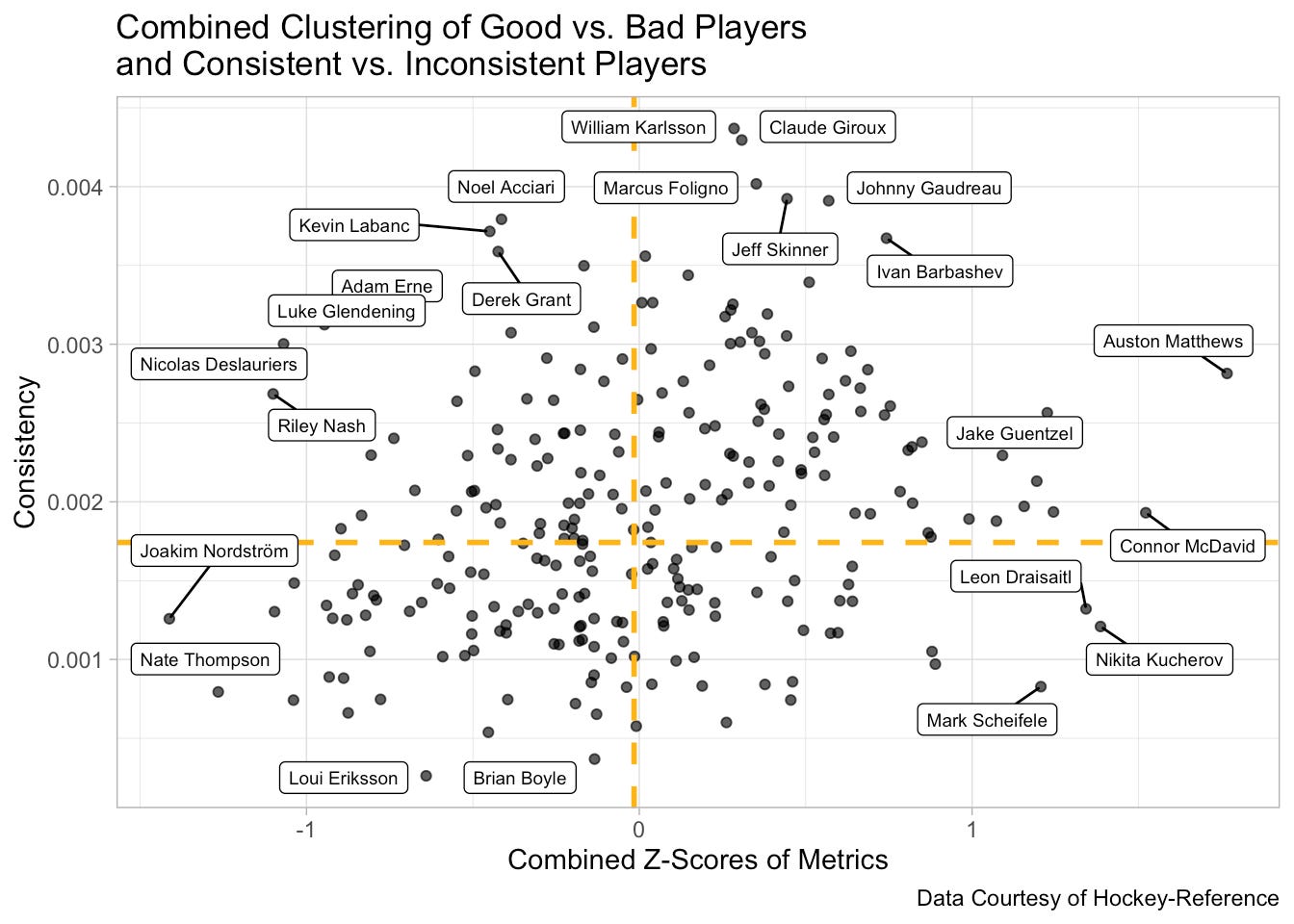
Research Question: How can we measure and value “consistency” among NHL forwards’ offensive performance?
Data Visualization: “Using the mean combined z-score, we cluster both the player’s mean z-score and their weighted mean change of each metric and combined metrics. The clustering results show that players located in the bottom-right quadrant of the graph are consistent and high performing players. Players in the bottom-left quadrant are consistent but poor performing players. Players in the upper-right quadrant are inconsistent but high performing players. Players in the upper-left quadrant are inconsistent and poor performing players. The quadrants are created through the medians of the weighted mean change and the mean combined z-scores of each metric and combined metrics.”

Interesting Takeaway: The students explored a number of different ways in trying to measure “consistency” (they’ll flip the y-axis for the conference in November!) - and at least with what they’ve done so far, it does not appear to be related with player salaries.
Examining batted passes in the NFL: A hierarchical approach to explaining variance of an unlikely event
Students: Lucca Ferraz (Rice University), Maggie Byers (Dickinson College), Yixin (Amelia) Yuan (University of Michigan)
External Advisor: Me… so not external in this case! However, we were provided the data on batted passes from football analytics pioneer Aaron Schatz at FTN - thank you Aaron!
Report Link: https://www.stat.cmu.edu/cmsac/sure/2024/showcase/football/report.html
Research Question: What factors are associated with batted passes in the NFL? Does QB height really matter?
Data Visualization: “This plot shows the estimates for all the fixed effects in our model, colored by year. Being on the log-odds scale, estimates greater than zero means that the variable corresponds to an increase in batted passes, estimates less than zero means that the variable corresponds to a decrease in batted passes, and estimates equal to zero show no impact on batted passes. Transparent intervals signify that the interval contains zero, or that the variable might not impact batted passes at all. We can see that middle passes and number of pass rushers are significant in both years.”
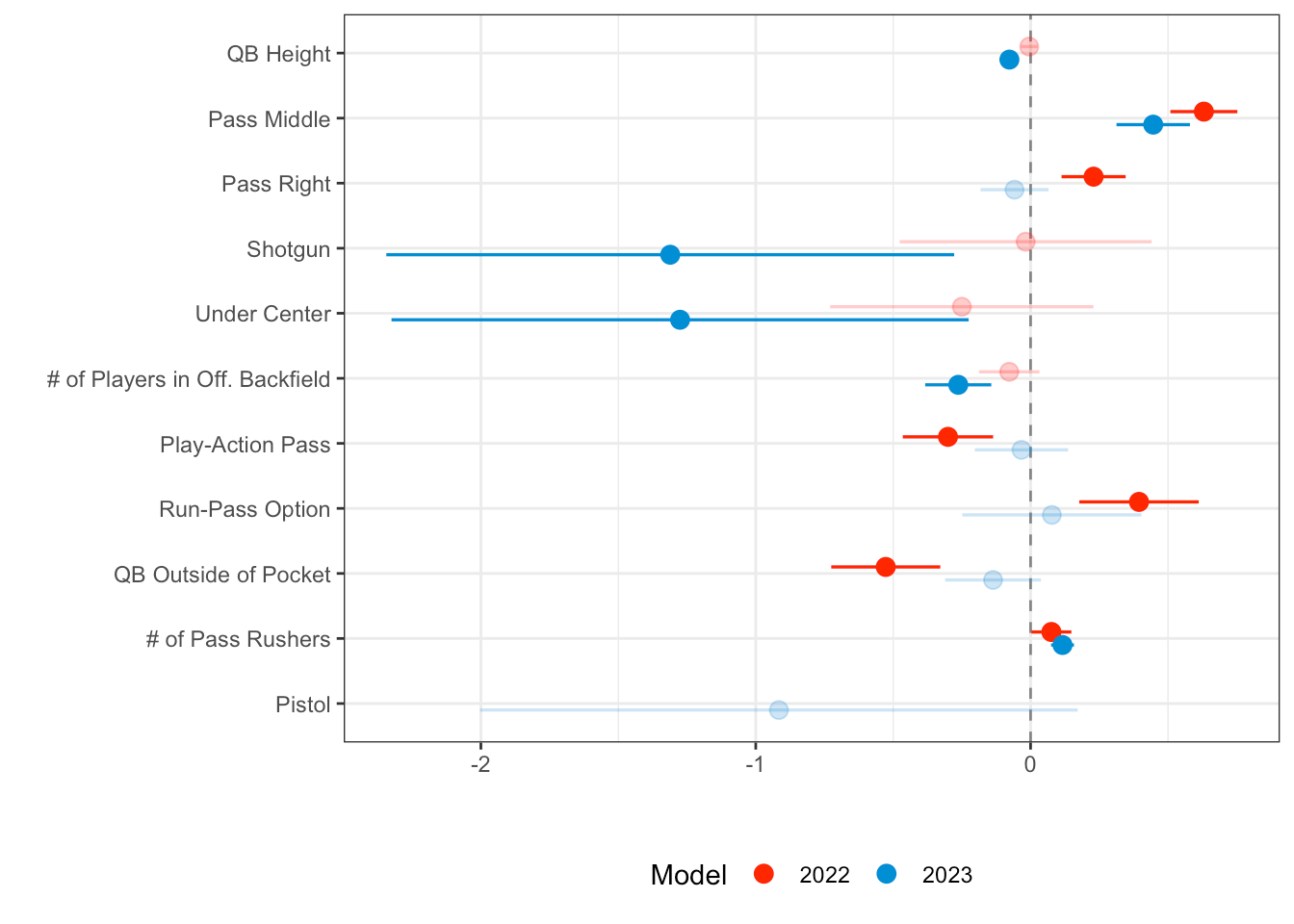
Interesting Takeaway: The students used a multilevel logistic regression model to study the sources of variation in batted passes for both the 2022 and 2023 NFL seasons. The students completely exceeded my expectations on this project with a fun story here: “One interesting case study we examined was the case of Bryce Young of the Carolina Panthers. A former number one overall pick in the draft at just 5 foot 10, questions were raised both in the pre-draft process and post-draft about his height. Young had an up-and-down rookie year as the Panthers finished just 3-13, so one is inclined to believe his height correlated with his struggles. Perhaps so, however, in the table above we see that Young’s random effect in relation to batted passes was actually the best in the NFL this past season! So does this dispel the notion that shorter quarterbacks have more batted passes? Well… not quite…” - you need to read the rest to find out! (Note: the player table takes a few seconds to load, so please be patient.)
Killer Defense: Evaluating Individual Defensive Contributions on the Penalty Kill
Students: Frithjof Sanger (Carnegie Mellon University), Ian A. Pérez (University of Arizona), Christina Vu (Texas Christian University)
External Advisor: Sam Ventura, Buffalo Sabres
Report Link: https://www.stat.cmu.edu/cmsac/sure/2024/showcase/hockey_sabres/report.html
Research Question: Using hockey tracking data, can we analyze passes in power plays to understand how defensive actions impact power play success rate?
Data Visualization: “The plot below is a heat map that displays the true pass success percentage of different locations around the ice. In the plot the left hand end of the rink represents the defensive zone and the right hand end of the rink represents the offensive zone. The plot shows that the largest concentration of low percentage pass locations are located around the net on the offensive side of the rink. This makes sense as there is likely to be a higher concentration of defenders around the passer in those locations than in other locations spread around the rink.”

Interesting Takeaway: The students built a pass-completion probability model to evaluate defender contributions, and revealed interesting insight: the passes that led to goals displayed lower estimates for probability of success, and Canada was the best team in terms of defensive contribution above average. I know nothing about hockey - but Canada at #1 probably passes the eye test…

The Wrong Stuff
Students: Liam Jennings (Robert Morris University), Tiger Teng (University of North Carolina at Chapel Hill), Belle Schmidt (St. Olaf College)
External Advisor: Sean Ahmed, Pittsburgh Pirates
Report Link: https://www.stat.cmu.edu/cmsac/sure/2024/showcase/baseball_pirates/report.html
Research Question: Stuff+ has become a popular metric for evaluating a pitcher’s arsenal, but are there any biases in Stuff+ with regards to types of pitches it overvalues or undervalues? Are there any trends over time?
Data Visualization: “Despite our previous observations that pitches with above-average horizontal movement have generated better-than-average whiff rates and xwOBA each year, Stuff+ still ranks the “best” fastballs as the pitches with excellent vertical movement and the fourth quadrant is mostly average or below-average. Visually, there appears to be some bias in Stuff+.”

Interesting Takeaway: The students created excellent visualizations throughout this report, and used a number of different modeling techniques with multiple response variables to reveal potential biases in Stuff+. One takeaway I’ll highlight here: “Velocity is consistently the most important characteristic across all years, underscoring its critical role in determining Stuff+. In contrast, for the xwOBA model, velocity’s importance sharply decreases by 2022 and becomes the least important by 2023. This suggests that while velocity is heavily weighted in the Stuff+ metric, its actual impact on at-bat outcomes (xwOBA) diminishes over time.”

Thanks for reading!