


'Tis the Big Data Bowl season
Thanks to Mike Lopez and others in the NFL league office, the NFL’s Big Data Bowl has evolved into an annual opportunity for anyone to contribute to the study of American football via the release of public player-tracking data. I honestly think this is the best sports analytics showcase event to participate in for someone that wants to “break into” the sports industry. Since it’s hosted on Kaggle, it’s easy to access the data and then eventually write-up your submission to share with the broader public. There’s no paywall. There’s no travel (unless you’re picked as a finalist to present at the NFL Combine!). You don’t need a Statistics PhD. Anyone can enter. And once you submit, you now have a public link to a body of work based on incredibly rich complex data to include in your data science portfolio and share with prospective employers, regardless if they’re in sports or not!
This year’s Big Data Bowl theme was tackling. While that is a very broad subject, it’s also one of the reasons why I love this event: a broad theme promotes creativity and leads to a variety of submission topics. This post will NOT be a review of Big Data Bowl entries. As a former judge of the competition, I personally find the act of publicly reviewing and ranking submissions to be disingenuous (especially since my name is explicitly attached to an entry this year). Instead, I’m going to encourage you to read through the entries on your own! I will of course shamelessly self-promote Carnegie Mellon affiliated submissions below, but first - here are two easy ways you can browse through Big Data Bowl notebooks:
View the official Kaggle page hosting all entries (as well as code people publicly posted): https://www.kaggle.com/competitions/nfl-big-data-bowl-2024/code (many people do not share on social media so viewing the submission page directly will likely lead you to surprising and interesting reading).
On Twitter/X (whatever you want to call it) you can search #BigDataBowl and find tweets/posts (again, whatever) by people sharing their work. These typically include the highlights and fantastic animations, such as this excellent example below (click on the image to view the animation):

Carnegie Mellon submissions
The following are highlights and links to Big Data Bowl submissions by CMU students (and myself) that you may find interesting:
No Edge No Chance
The Impact of Setting the Edge on Zone Run Plays
Authors: Shane Hauck, Marion Haney, Devin Basley, Vinay Maruri
Submission notebook: https://www.kaggle.com/code/devinbasley26/no-edge-no-chance
This submission by four CMU Statistics & Data Science Master of Science in Applied Data Science (MADS) students was a collaboration with CMU football coaches (Head Coach Ryan Larsen and Defensive Coordinator Ben Gibboney) on the importance of “setting the edge”. This coaching track submission was motivated by conversations with the coaches and captured the importance of the defense forcing directional changes in RB movements. They created some excellent visualizations and animations displaying the value of directional changes such as this figure, displaying that it’s likely better for the offense if the ball-carrier maintains the same direction of movement:

They walk through the creation of an Edge Intensity Rating inspired by the coaches and also created a Shiny app to demonstrate a potential coaching tool with the provided data (link to app here). For a period of time, this submission was the number one trending notebook on Kaggle! Not just the Big Data Bowl, ALL OF KAGGLE.
Momentum-based fractional tackles
Authors: Quang Nguyen, Larry Jiang, Meg Ellingwood, and me
Submission notebook: https://www.kaggle.com/code/tindata/momentum-based-fractional-tackles
Two CMU Statistics PhD students (Quang and Meg), one CMU Neuroscience PhD (Larry), and myself walk into a bar… Okay not really, more like zoom meetings and my office. Anyway - we introduced a new metric: momentum-based fractional tackles. Instead of pursuing machine learning models, we decided to think about the observed player-tracking data and how we could create a new definition for tackling only based on observed quantities. This led to the idea of looking at the ball-carrier’s forward progress, as measured by momentum in the direction of the target endzone and to see if we could attribute changes in this directional momentum to defensive players. This returns back to the fundamental goal of tackles: to halt the forward progress of ball-carriers. Any defender that aids in this process should receive credit. Through our introduction of contact windows based on a simple distance threshold (determined based on the provided first_contact and tackle events), we measure changes in the forward progress of the ball-carrier and attribute those changes to each defender within the contact window. This provides us with a continuous measure of performance for defenders, our momentum-based fractional tackles, enabling us to move beyond the binary designations of tackle / missed tackles or assists. One of my favorite aspects of this framework was observing how overstated tackles and assists likely are, and how much more credit defensive linemen should receive in halting ball-carrier momentum:

This submission is relative simple and easy to compute. But what I’m hoping for, is that it can be a new metric for defensive performance to improve upon over time. The next steps are of course to turn this into an actual statistics paper, with a focus on modeling the change in momentum directly and understand what explains variation in fractional tackles.
Spilling vs. Boxing: How Defenses Fit Counter
Author: Abhi Varadarajan
Submission notebook: https://www.kaggle.com/code/abhishekvaradarajan/spilling-vs-boxing-how-defenses-fit-counter
Last but not least is a submission by CMU freshman(!) Abhi, a student that is passionate about understanding football scheme and connecting it with analytics. In my conversations with Abhi so far, I have learned that he knows way more about football already than I ever will. For example, he can draw this off the top of his head:
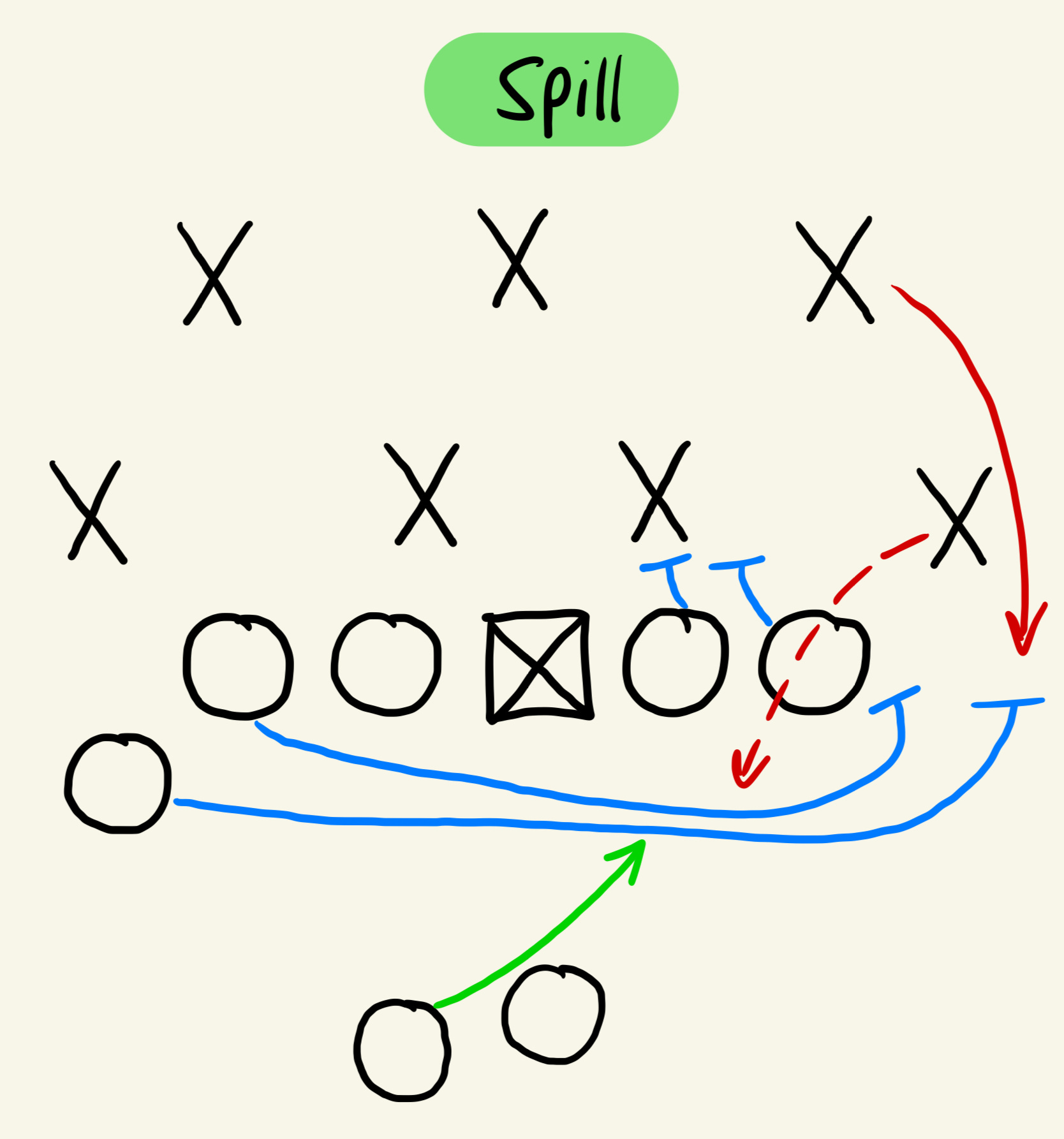
Fortunately, he took up the opportunity to enter the Big Data Bowl for the first time (I suspect the first of many until he’s hired by an NFL team) and conducted an analysis on how players and teams play defense against counter runs. Although the limited data makes it hard to draw conclusions, his conclusions are interesting and I encourage you to read through his submission (especially if you’re interested in football schemes and play-calling).
Thanks for reading!