
Paper:
Clustering of football players based on performance data and aggregated clustering validity indexes by Serhat Emre Akhanli and Christian Hennig, published in Journal of Quantitative Analysis in Sports (2023).
Journal URL: https://www.degruyter.com/document/doi/10.1515/jqas-2022-0037/html
Public URL: https://arxiv.org/abs/2204.09793
Background:
Before reading any further, if you’re looking for fascinating results on clustering players in soccer then STOP reading this and do something else. This paper uses older data, so the actual results are not that interesting in my opinion. However, the paper is interesting from the perspective of how we use clustering techniques in sports analytics research. If that excites you, then continue reading - otherwise enjoy the rest of your day and maybe the next paper will be more relevant to you.
I remember seeing this paper appear on arXiv awhile back and immediately thought I need to read this for a couple of reasons: (1) clustering is a subject near and dear to me since it was my first real research area, and (2) clustering is everywhere in sports analytics. When I refer to clustering in this post, I’m referring to techniques used in grouping observations together such as identifying types of players in soccer1. The authors provide fantastic commentary on clustering throughout this paper, relevant for anyone using common clustering techniques in sports analytics projects. But to put it bluntly, I think this paper is hard to read. To be clear: I do NOT think it is a poorly written paper - in fact, it’s a polished, well-written paper. But the difficulty in reading it stems from the fact that it is a more traditional statistics methods paper, not one necessarily designed for the sports analytics audience. So I figured that trait made it an ideal starting candidate for Open Source Sports.
Why You Should Care:
Clustering techniques are widely used in sports analytics, but evaluating the quality of clustering results (like choosing the method or number of clusters) can feel pretty arbitrary. This paper discusses a variety of different ways to evaluate clustering performance in a more formalized manner. Do NOT think this is a one size fits all “solution” to clustering, but rather it gives you more insight into how to think about clustering results more carefully (hence the title of this post!).
The authors consider two different use cases in the context of clustering soccer players:
Player types: To help understand how teams are composed, group players into a relatively low number of large clusters that represent broad types of players / archetypes.
Comparable players: If you're instead interested in finding the nearest comparable players, then group players into a much higher number of small clusters.
These two use cases are very different from each other. The implication from this is that how we assess the clustering quality will also be different!
The authors walk through the steps for measuring dissimilarity between players with mixed data, meaning data consisting of different types of variables: categorical and quantitative. More often than not, when someone in sports analytics is using a clustering technique, they are only using quantitative variables and relying on Euclidean distance as their measure of dissimilarity. But we have great flexibility in how we measure dissimilarity between observations, and this paper provides a good walkthrough of these steps (see more below in the Methods section if interested).
If you’re looking for code, you can access the R package used by the authors for implementing their methodology: https://cran.r-project.org/web/packages/fpc/index.html
Methodology Highlights:
A core component of this paper is the walkthrough of measuring dissimilarity between players in the considered dataset (Section 2), since the authors used mixed types of variables. This is a great part of the paper because it demonstrates how there are an infinite number of ways in which you can define the dissimilarity between observations in your dataset. And even if you are only working with quantitative variables, YOU DO NOT HAVE TO USE EUCLIDEAN DISTANCE! The defaults in your code are just that, defaults! Free your mind and consider a more customized process for measuring differences between your observations. The authors in this paper consider five different stages in this process:
Representation: before doing anything fancy, just think carefully about how you define your variables, such as differences in overall counts versus sub-categories (example: goals versus proportion of goals made for different shot lengths).
Transformation: When you typically think about transformations, you may think about taking the log or square root or something else. While the authors use a form of log transformation with a variable specific adjustment (read the paper for that part), I found this statement to be incredibly insightful (from Section 2.2):
“For example, many players, particularly defenders, shoot very rarely during a game, and a few forward players may be responsible for the majority of shots. On the other hand, most blocks come from a few defenders, whereas most players block rarely. This means that there may be large absolute differences between players that shoot or block often, whereas differences at the low end will be low; but from the point of view of interpretation, the dissimilarity between two players with large but fairly different numbers of blocks and shots is not that large, compared with the difference between for example, a player who never shoots and one who occasionally but rarely shoots.”
I love this example, because it demonstrates how differences may not be equal in meaning across your range of values - which also means you must be careful in how you apply transformations. You must understand the meaning of differences between observations based on context.
Standardization: This is a subtle thing that I consistently see students forget to do. You need to be careful when measuring some notion of dissimilarity with regards to the units of your variables. Imagine if you are using Euclidean distance and one variable is on the scale of millions, ranging from 1 to 100 million, while another variable is on the scale of 0.00001 to 0.000013. The first variable on the scale of millions will dominate your distance calculation. We typically use some sort of standardization (compute z-scores: subtract the average and divide by the standard deviation) to put the variables on an equal playing field. But you might not want equal treatment, you may think one variable matters more relative to others. Well in that case…
Weighting: Building off the previous stage, you can adjust weights to your different variables when computing your dissimilarity. Deciding what your variable weights should be is a really difficult problem. In the “simplest” sense, you can imagine just deciding which subsets of variables should be used (variable selection for clustering - again, not an easy problem!). How you determine that should be motivated by the types of clustering quality indices described more below.
Aggregation: This is the final step of just combining the measures of dissimilarity for each of the considered variables. Meaning they can be different for each variable: one could be squared difference, another is absolute difference, another for a categorical variable is some difference you make up, etc. Just imagine taking Euclidean distance and breaking it up by the different variables, then add in weight multipliers to change which variables dominate your calculation. This should give you some sense of the aggregation in Section 2.5. (I am ignoring some more particular details they have about sublevel variables and variables within groups).
While the authors ultimately use a collection of difference measures of clustering performance, and then aggregate them in a way to provide a one number summary indicating how good a particular set of clustering results are, I’m going to completely gloss over that to just highlight three of the considered indices:
Average within-cluster dissimilarities: This is probably the most basic measure of clustering performance. You want observations in the same cluster to be very similar to each other. But there’s a tradeoff to this… if you place every observation in its own cluster then BAM, you have the optimal solution! That’s of course useless, but if we’re still bad and choose an immensely large number of clusters then we’ll mislead ourselves into thinking we have a great clustering result if this was the only index considered…
Separation index: This is my personal favorite measure of clustering quality. Beyond wanting observations in the same cluster to be similar, this should go without saying, but we want observations in different clusters to be different from each other! You can imagine visualizing an actual gap between two clusters of points. While I see clustering used quite frequently in sports analytics, I’m often very skeptical that people are displaying clustering results with meaningful separation. The authors provide a great way of computing a separation index in Section 3.3.2. In this case, the idea is to look at the border players of a cluster, the players on the boundary - the ones you’re most uncertain about or far away from the cluster centers. Compute how far away those boundary players are from boundary players in other clusters. Are they closer to another cluster’s boundary players than the interior players of their own cluster? That would be a sign you have clusters that are not well separated from each other.
Stability: While we do not know the true clustering labels (because they don’t exist, and they will never exist regardless of your toy textbook dataset example), it’s appealing to think about a way to resemble how we evaluate prediction models out of sample. This translates to stability in clustering where we want observations to be clustered together, regardless of differences in the sample dataset used to construct the clustering. The authors walkthrough one such approach via bootstrapping in Section 3.3.5 that I implore you to read if you’re interested in assessing clustering stability in your own projects.
Key Results:
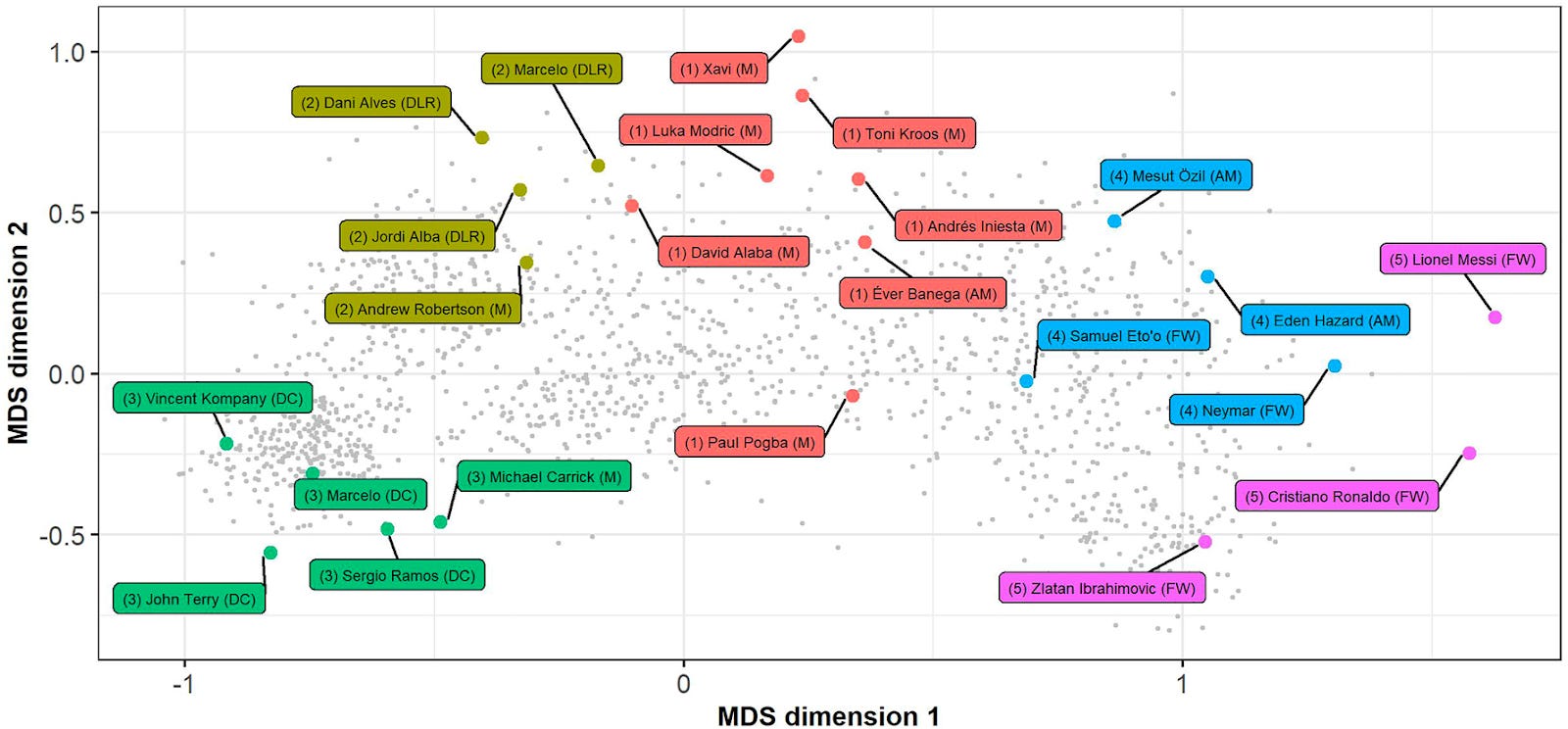
In future posts, this will likely be the largest section. But for this paper I’ll just include their main player type results in Figure 3. Note that this is a multi-dimensional scaling (MDS) projection of their variables into 2D. Meaning, based on their custom calculation of dissimilarity, they created a plot displaying the individual players where the observed differences between points is trying to preserve the original dissimilarity calculation (so two players that are close on this plot, have low dissimilarity based on the original set of variables). Again, I don’t find the results interesting because it’s old data (shocking, Messi, Ronaldo, and Zlatan are together - who would’ve guessed that…).
Concluding Thoughts:
I probably wrote way too much in this post, but hopefully you found the commentary useful for yourself when thinking about using clustering techniques. The results of this paper do not matter to me, but the process and careful consideration of dissimilarity construction and various ways to measure clustering quality are what matter. I encourage you to NOT just naively use default functions for clustering - but rather think deeply about what defines differences between your observations and what goal you’re trying to achieve with clustering in the first place.
I will try to find a more results-based paper for next time, but please provide any feedback you have - what you liked, didn’t like. The general structure will follow what I did here - starting with main takeaways, before going into more details. But I will never cover everything in the paper, because you can just go to the papers directly if you want all the gory details.
Last thing - I am going to stick with published papers, and will avoid discussing papers that are still preprints. The main reason: I’m an associate editor for the Journal of Quantitative Analysis in Sports (and a reviewer for many other journals) so I do NOT want to taint the review process in any way. Instead I’ll just focus on papers that already cleared this hurdle.
Thanks for reading!
If you want to learn more about clustering, then I recommend you check out ‘Introduction to Statistical Learning in R’ - 2nd Edition which is available here: https://www.statlearning.com/. The authors also have slides on the unsupervised learning chapter which includes material about PCA and clustering here: https://web.stanford.edu/~hastie/ISLR2/Slides/Ch12_Unsupervised_Learning.pdf
Very interesting stuff, thanks for sharing! I have some experience in doing this kind of modeling for my work in football analytics. I do believe that the choice of variables and the way they are normalized (e.g. by minutes played, number of touches, share of team totals, % of an event subtype w.r.t. total etc.) is as (if not more) important than the technicalities of the clustering process in itself. Would you agree with that?