
Down, set, hut!
Explaining variability in snap timing on plays with motion
Background
For some reason that I cannot explain, I am fascinated by snaps in football. I have this belief that snap quality is analogous to catcher framing in baseball. Maybe there is meaningful value in consistent high-quality snaps that affects the offense? My dream is to see snap placement charts along a QB’s body similar to baseball strike zone displays, with snap quality leaderboards for centers similar to the catcher framing leaderboards on baseballsavant.
This post does not make that dream a reality… However, last year I had a great conversation with the inimitable Sam Schwartzstein (who’s leading the slick TNF Prime Vision broadcast) where I discussed this idea with him among other things. Back in the day, Sam was the starting center at Stanford so he had several great ideas related to this. One concept he brought up (that I had not thought about before) was the role of the QB in managing snap timing in the presence of motion. Fast-forward to the announcement of this year’s Big Data Bowl theme, pre-snap to post-snap predictions which includes annotations of motion, and I decided to pitch this idea to students in the Carnegie Mellon Sports Analytics Center (CMSAC) research lab. Fortunately, PhD student (and data visualization wizard) Quang Nguyen decided to run with the project and wrapped it up in record time1 - resulting in the published notebook: Down, set, hut! Explaining variability in snap timing on plays with motion.
Modeling snap timing variability
I have written about CMSAC Big Data Bowl submissions in previous years, so I’ll keep a similar format here - pointing you to read through the full notebook on Kaggle.
Authors: Quang Nguyen2, Ron Yurko
Submission notebook: https://www.kaggle.com/code/tindata/down-set-hut/notebook
The quick version of this notebook is as follows:
For every passing play with receivers in motion at snap and also running a route, we observe the snap timing: the amount of time between the start of the receiver’s motion and when the snap takes place.
Before diving into the basics of the model, Quang fit a Gaussian mixture model to identify motion type “clusters”3. This approach is just a starting point, but it’s a simple proxy to account for types of motion in the following model. We anticipate that there will likely be notebooks completely dedicated to this problem of detecting types of motion - which I look forward to reading and will probably incorporate into the manuscript version of this work.
The fun part: we model snap timing following a Gamma distribution with a multilevel model. This allows us to account for relevant fixed effects (such as motion type) to capture mean shifts in snap timing along with random effects for the QB, motion receiver, and opposing defense. All of this is done a Bayesian framework using brms, enabling us to quantify uncertainty with posterior distributions for all of the parameters of interest. The even more fun part: we also use QB random effects for the shape parameter of the Gamma distribution, enabling us to estimate differences in the snap timing variability between QBs.
We focused on the QB shape random effects for this notebook, and the results are pretty fun4: Patrick Mahomes is at the top in displaying the highest snap timing variability, Daniel Jones is last. Why should we care about this model’s output describing differences in snap timing variability between QBs? Because, as it turns out, snap timing variability appears to be associated with play outcomes across all passing plays -not just the motion passing plays considered in the model! The two scatterplots below capture this with “havoc rate” along the y-axis and the posterior means for the QB shape random effects along the x-axis:
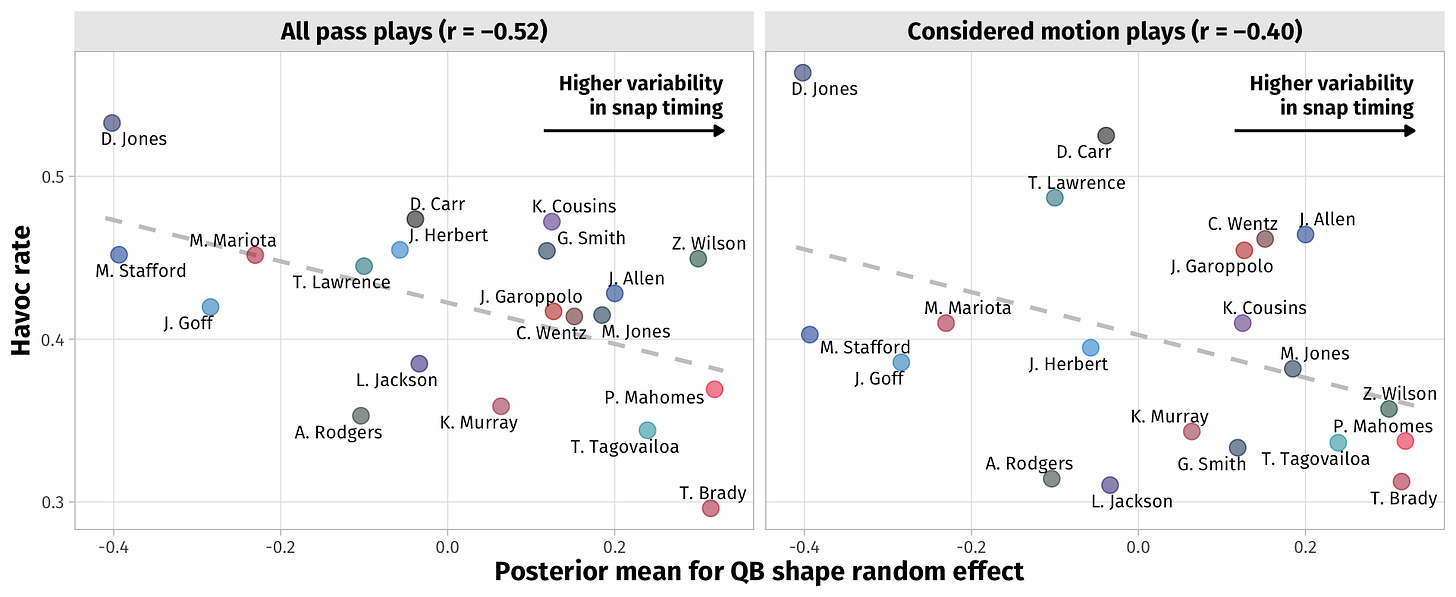
Our discussion wraps up with the limitations of this work, but I’m pretty happy with how this turned out. We observe meaningful differences between the snap timing variability of QBs5, with some indication that it’s potentially related to the QB’s awareness or pocket presence.

It will be interesting to replicate this work on a larger sample of data, but I’m excited for this to be turned into an academic paper in the months ahead. And maybe one day we’ll get to see snap placement quality charts…
Goodbye Open Source Sports
I first started this Substack as a continuation of the Open Source Sports podcast, where I intended to write about a published sports analytics paper in each post. I have failed miserably at managing that! So I’ve decided to rebrand this Substack to be my new outlet for sharing my sports analytics research, highlighting the work of others, and my general thoughts on the field. It felt appropriate to update the name to reflect my brand6 and what I’m trying to accomplish: which is to educate and promote statistical thinking in sports analytics. Hence the name change that I will be sticking with moving forward - but the previous URLs will redirect to this updated site.
You can expect more frequent (shorter) posts in the future that are analogous to twitter threads I used to put together. So stay tuned for more Statistical Thinking in Sports Analytics content, including more CMSAC Big Data Bowl submissions, and thanks for reading!
I literally cannot stress enough how relieved I am that this is already submitted.
Quang did all the work, I was barely involved. All I did was give him a little nudge out of the door.
Okay this is a sensitive topic for me… GMMs are just trying to fit Gaussian distributions to your data. These do not necessarily correspond to separated “clusters” - the simplest example is to think of a unimodal, skewed distribution which could be reasonably approximated by a mixture of Gaussians despite the fact it’s only one “cluster”. That does not mean that GMMs cannot be used to detect clustering structure, it’s just that you need to keep this mind when interpreting the output.
This year’s sample of data was from the first nine weeks of the 2022 season, hence why Brady is in there at number two behind Mahomes (which is appropriate IMO).
Limitation! This could be due to the play calling scheme or even the center, but that would be difficult to tease apart from the QB with a model.
And to actually include both ‘statistical thinking’ and ‘sports analytics’ in the title. I honestly have no idea why I settled on ‘Open Source Sports’, that sounds like something that is just focused on sports software… oh well, moving on.
Great stuff! An analogous concept in basketball might be a passer hitting a jump shooter in their shooting pocket with an on-target delivery. Could use such a measure to quantify passing skill, as well as variability in shooting skill (i.e., how dependent a shooter is on an on-target pass).